Week-2-Lab-Report
Debugging, Using Diff, and Using Bash (Week 10 Lab Report #5)
Created by: Erwin Madjus
Last Edited: March 10, 2022
Background Information:
Choose any 2 tests from the 652 commonmark-spec tests where your implementation (or a representative implementation from your group) had different answers than the implementation that was provided in Lab 9.
From the implementation that was found in the following repository: mark-down-parse
Explain:
How you found the tests with different results (Did you use diff on the results of running a bash for loop? Did you search through manually? Did you use some other programmatic idea?)
Answer: To find the tests with different results with one being ran on my repository actual-markdown-parse repository and the other being ran on the markdown-parse repository (created by the professor), I did the following:
- First, open up the ProfessorRepository on VSCode. The directory
test-files/in the professor’s respository had 1000 files and 650 test input.mdfiles which did not have any names. (Difficult to keep track of the test files.) To fix that we had to fix the code in thescript.sh. Add the following: (Access this by typing the commandvim script.sh)
for file in test-files/*.md;
do
echo $file
java MarkdownParse $file
done
Run the command bash script.sh and you will now see the output with a name.
- The terminal gets filled up quick when running the
bash script.shcommand so to avoid that problem you can redirect the output to be displayed and outputted onto a.txtfile. You run the following command:bash script.sh > results.txt
After waiting for that command to fully run, you then type either one of these commands to see the output: vim results.txt or cat results.txt
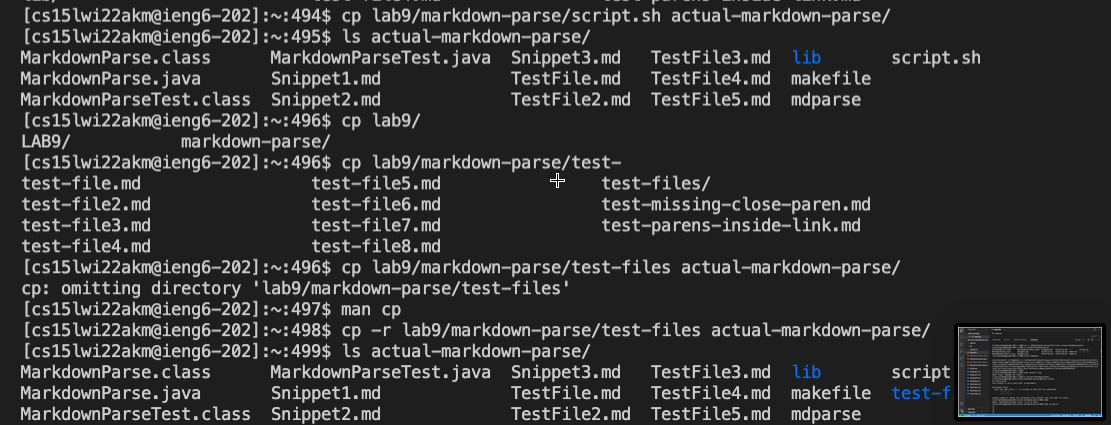
- After that, you then have to log into
ieng6. There you copy thescript.shandtest-files/into yourmarkdown-parsedirectory. You do that by doing the following:
In my case you would type the following in the terminal, when logged into ieng6:
Generally, you follow the steps listed below:
cd ~ # go back to your home directory
git clone ... your-markdown-parse ...
# these commands assume that the provided course one is stored in
# cse15l-markdown-parse and yours was cloned to your-markdown-parse
cp -r cse15l-markdown-parse/test-files your-markdown-parse/
# The -r option above stands for "recursive", which means that files and other
# directories inside the given directory are copied recursively
cp cse15l-markdown-parse/script.sh your-markdown-parse/
Afterwards, you run the following command: bash script.sh > results.txt
After waiting for that command to fully run, you then type either one of these commands to see the output: vim results.txt or cat results.txt
-
After you have the 2
.txtfiles created with one having the output of the professor’s program and the other with the output from your program, you can use the programdiff. -
While logged into
ieng6, you run the following command:
In my case, I ran the following command on the terminal:
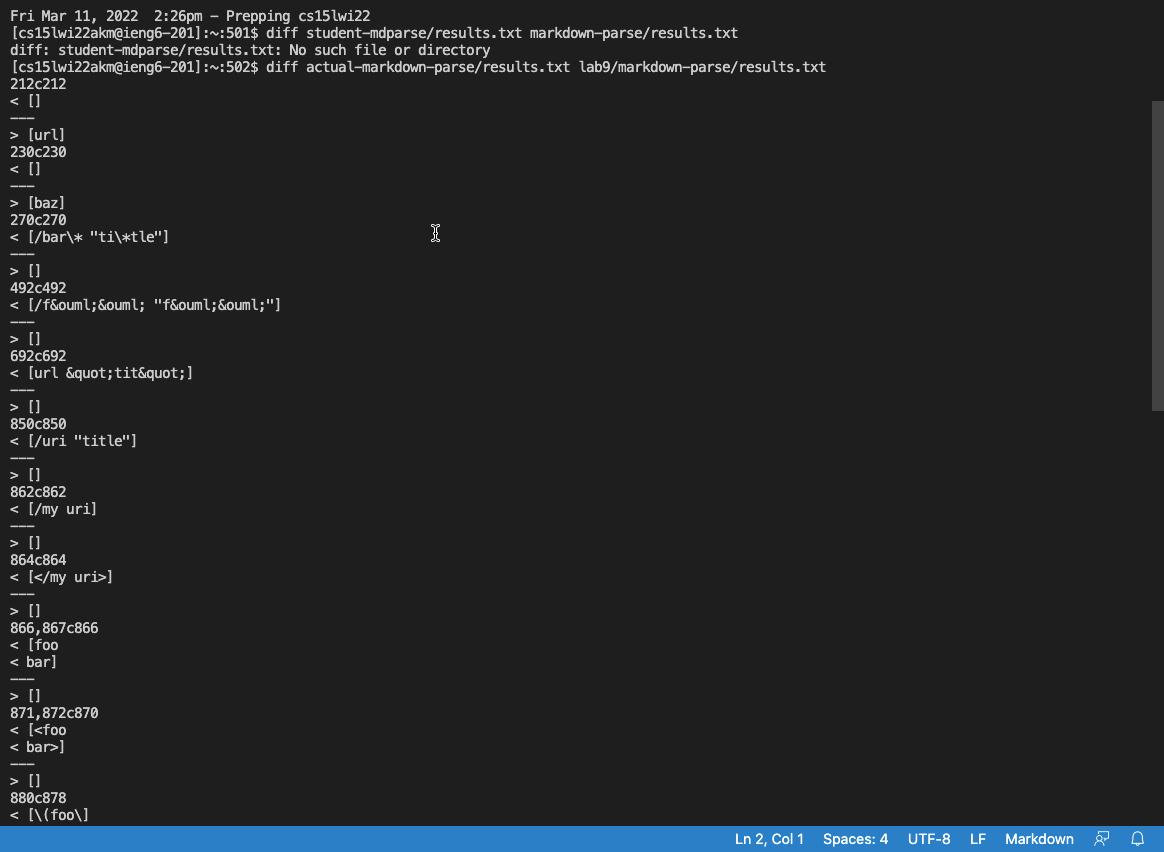
diff actual-markdown-parse/results.txt lab9/markdown-parse/results.txt
You can see the command and the output in the screenshot right below:
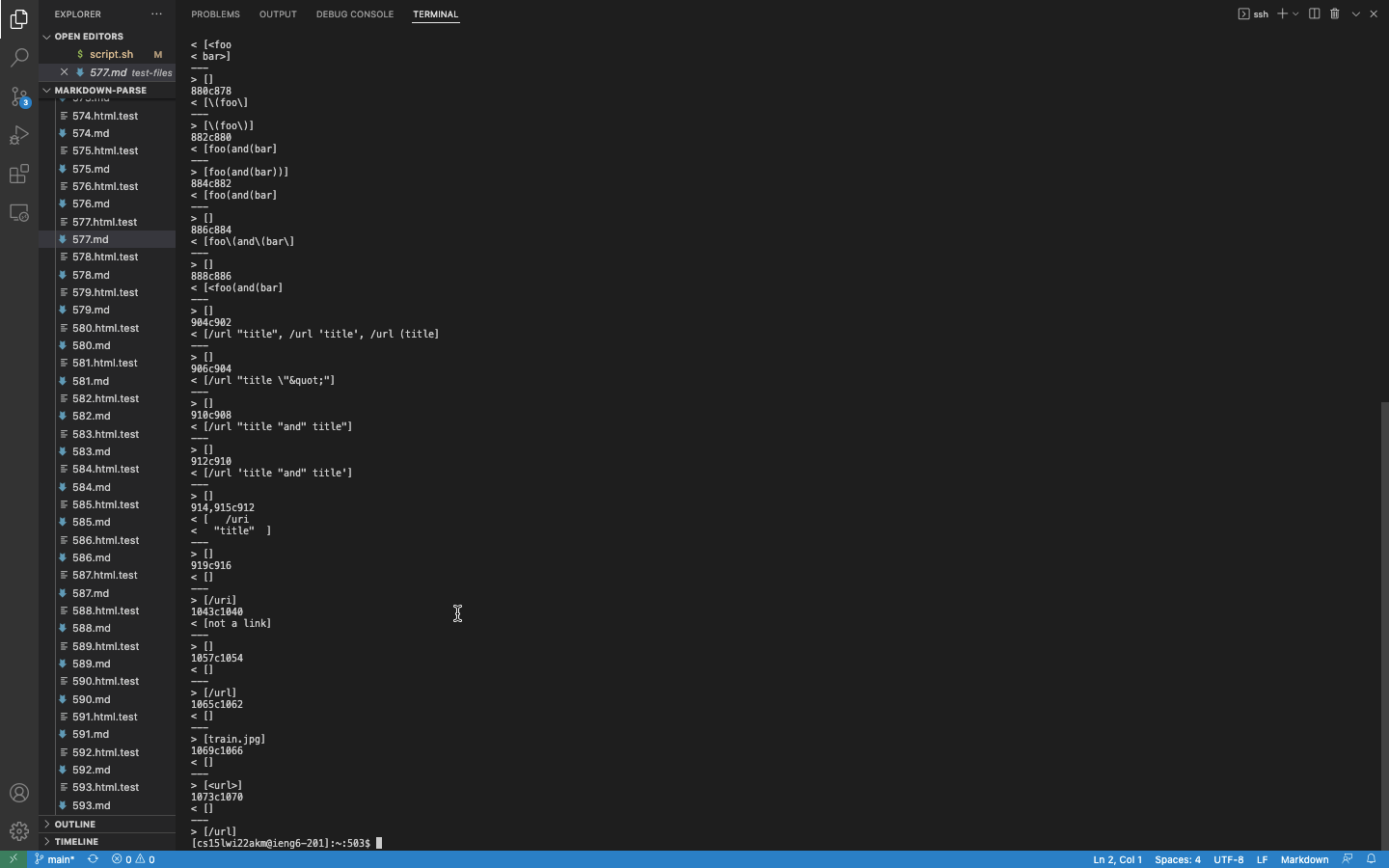
diff student-mdparse/results.txt markdown-parse/results.txt
where the paths and filenames are the ones that are unique to your repository and the professor’s repository.
You should get the following output: (This screenshot only contains the tests that I will be checking later during this lab, not the entire ouput).
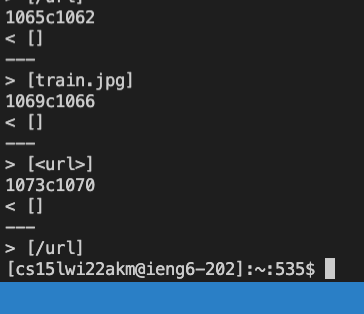
- To read this, you first see a line
like 92c92, where theresults.txtin thestudent-mdparsedirectory, the line contained[], while on line92of themarkdown-parse/results.txtdirectory, the line contained[/foo]. If we look at line92, in those files, that’s the test output for thefile 14.md
Test #1:
Question: Describe which implementation is correct, or if you think neither is correct, by showing both actual outputs and indicating what the expected output is.
Answer: To determine which implementation is correct in this case depends entirely on the fact if the programmer decides to make an image link an actual link or not.
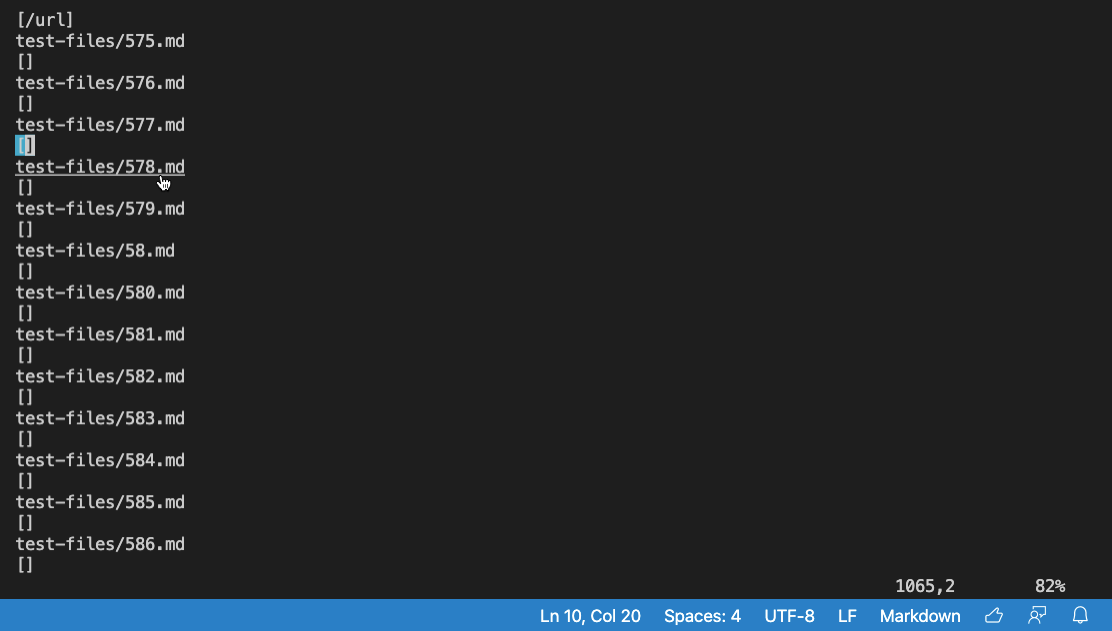
The Code Difference was found on the test-files/577.md
What is in the test-files/577.md file: 
If the programmer chooses to make an image link not an actual link, then my implementation is correct.
My implementation is correct because it checks to see if the link is an image link or not, since its an image, it does not consider it an actual, hence why it is not displayed.
Both Actual Outputs:
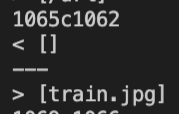
- Where line
1065is in theactual-markdown-parsewhile line1062is in themarkdown-parse
In my case, the expected output is the output that was displayed using my implementation: [].
1065c1062
< []
---
> [train.jpg]
If the programmer chooses to make an image link an actual link, then the professor’s implementation is correct.
1065c1062
< []
---
> [train.jpg]
In this case, the expected output is [train.jpg] because the implementation made it so that the program will allow image links to be actual links.
Question: For the implementation that’s not correct (or choose one if both are incorrect), describe the _bug (the problem in the code). You don’t have to provide a fix, but you should be specific about what is wrong with the program, and show the code that should be fixed.
Answer: In order to fix the problem, it can go both ways, depending if you decide to make an image link an acutal link or not.
If you decide to make an image link not an actual link you would have to do the following:
The professor’s implementation is incorrect.
-
Open up the
MarkdownParse.javafile and make sure to add lines of code that checks for the following. -
add an
ifstatement with the following conditions: one that checks to see ifnextOpenBracket != 0; one that checks to see ifmarkdown.charAt(nextOpenBracket -1)== -'!')then inside the curly brackets add the following:currentIndex = nextOpenBracket+1; continue
Something like the following:
if (nextOpenBracket != 0 && markdown.charAt(nextOpenBracket -1) == '!'){
currentIndex = nextOpenBracket+1;
continue;
}
-
Adding the following will cause the program to change the currentIndex to the value that contains the first open bracket, skipping this link entirely because it does not meet the conditions of an actual link. It skips over this link because there is an
!the link. -
Since some images have a format similar to that of a website, we have to make a fix that can prevent adding a link.
If you decide to make an image link an actual link you would have to do the following:
My implementation is incorrect.
- To fix it, I would simply have to remove the check that I have created.
if (nextOpenBracket != 0 && markdown.charAt(nextOpenBracket -1) == '!'){
currentIndex = nextOpenBracket+1;
continue;
}
-
By removing this condition on my
MarkdownParse.javafile, my program would not check to see if there is an!in the link. -
That would make it so, both implementations output the same output, the expected output.
Test #2:
Question: Describe which implementation is correct, or if you think neither is correct, by showing both actual outputs and indicating what the expected output is.
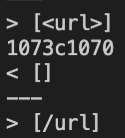
- Where line
1073is in theactual-markdown-parsewhile line1070is in themarkdown-parse
The expected output would be []
Answer: My implementation is correct because in my case, the link inside of the parenthesis is not the correct form of an actual link, it does not end with a common ending like .edu or .com. My implementation also catches that there is an ! before the first bracket, the link is also not an actual link in this case.
The expected output is the output that was displayed using my implementation: [].
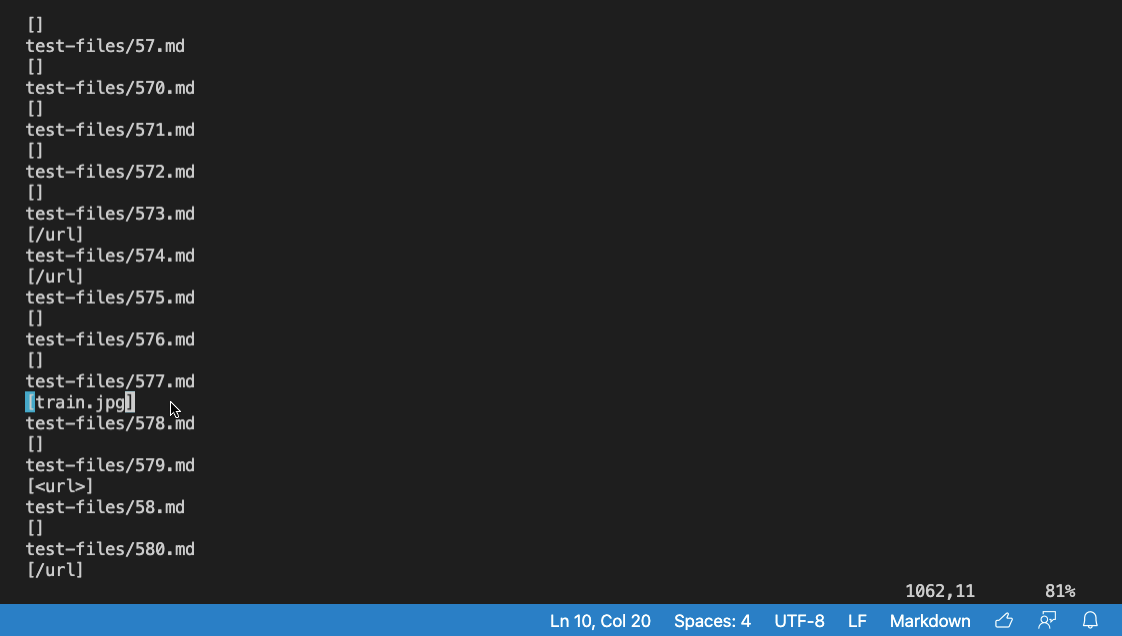
The Code Difference was found on the test-files/580.md
What is in the test-files/580.md file: 
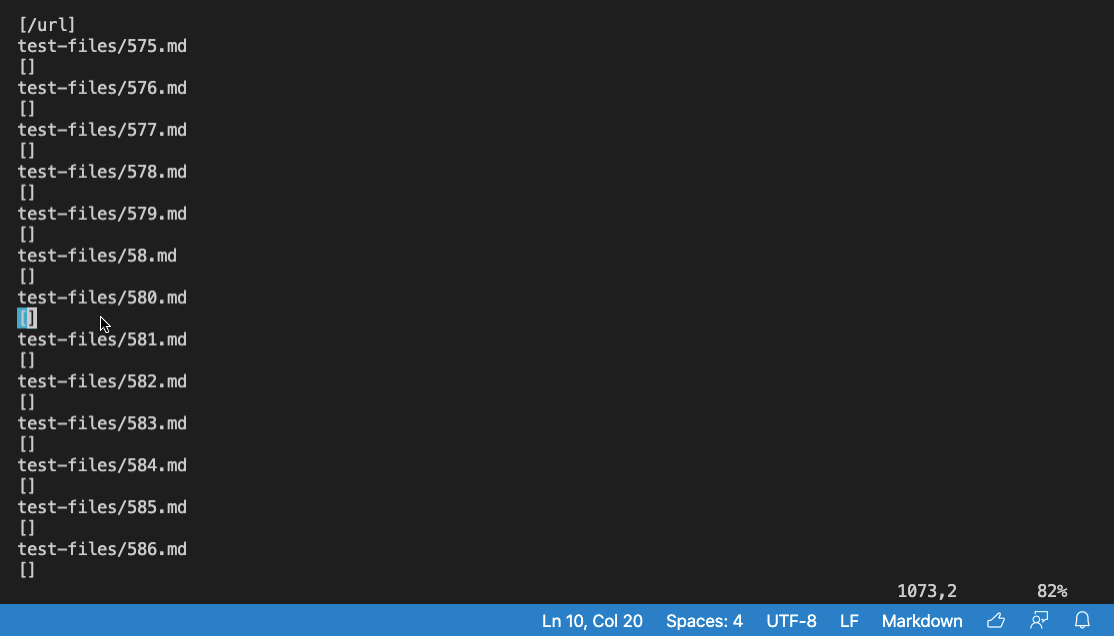

Output:
1073c1070
< []
---
> [/url]
Question: For the implementation that’s not correct (or choose one if both are incorrect), describe the _bug (the problem in the code). You don’t have to provide a fix, but you should be specific about what is wrong with the program, and show the code that should be fixed.
Answer: The professor’s implementation is incorrect because of the following:
-
The
MarkdownParse.javafile and the professor’s implementation does not have a condition that checks the actual link is in not in the format of an actual link, it is/urlwhich is not an actual url likesomething.comorschool.eduetc. -
To fix the problem that the link inside of the parenthesis is considered a link when it is not the correct format, you should add a condition to check to see if string inside of the parenthesis contains any of the endings of a website or link:
.com,.gov,.edu,.org,.net, and etc. -
In addition, the implementation does not check to see if the program should consider an image link to be a valid link or not, in my case, the image link should not be considered a link.
To fix the problem of deciding that the program should not consider an image link to be an actual link, you should do the following:
- add an
ifstatement with the following conditions: one that checks to see ifnextOpenBracket != 0; one that checks to see ifmarkdown.charAt(nextOpenBracket -1)== -'!')then inside the curly brackets add the following:currentIndex = nextOpenBracket+1; continue
Add the following condition in the MarkdownParse.java file:
if (nextOpenBracket != 0 && markdown.charAt(nextOpenBracket -1) == '!'){
currentIndex = nextOpenBracket+1;
continue;
}
By fixing these 2 problems, you should get the expected output of [].
All Code Differences:
Outputs on the terminal:
230c230
< []
---
> [baz]
270c270
< [/bar\* "ti\*tle"]
---
> []
492c492
< [/föö "föö"]
---
> []
692c692
< [url "tit"]
---
> []
850c850
< [/uri "title"]
---
> []
862c862
< [/my uri]
---
> []
864c864
< [</my uri>]
---
> []
866,867c866
< [foo
< bar]
---
> []
871,872c870
< [<foo
< bar>]
---
> []
880c878
< [\(foo\]
---
> [\(foo\)]
882c880
< [foo(and(bar]
---
> [foo(and(bar))]
884c882
< [foo(and(bar]
---
> []
886c884
< [foo\(and\(bar\]
---
> []
888c886
< [<foo(and(bar]
---
> []
904c902
< [/url "title", /url 'title', /url (title]
---
> []
906c904
< [/url "title \"""]
---
> []
910c908
< [/url "title "and" title"]
---
> []
912c910
< [/url 'title "and" title']
---
> []
914,915c912
< [ /uri
< "title" ]
---
> []
919c916
< []
---
> [/uri]
1043c1040
< [not a link]
---
> []
1057c1054
< []
---
> [/url]
1065c1062
< []
---
> [train.jpg]
1069c1066
< []
---
> [<url>]
1073c1070
< []
---
> [/url]